Studying Learning in Continual Learning
When does continual learning require learning? Methods for continual learning in large language models (prompting, fine-tuning, reinforcement learning, and context compression) are usually studied in isolation. We propose a framework that lets us evaluate them together on the same sequential benchmarks, and find that the data and task conditions determine whether continual learning requires learning.
*Equal contribution· 1UC Berkeley· 2Independent· 3Capital Fund Management
arXivcoming soon Codecoming soon
One · Premise
Continual learning is not one problem.
For decades, continual learning was defined as the problem of mitigating catastrophic forgetting: how do you learn task B without erasing task A? Classic approaches kept old skills intact by adding task-specific parameters on top of a shared model or partitioning parameters into a separate set per task, and benchmarks measured a model's retention across a sequential chain of unrelated tasks.
In the era of large language models, the problem is more nuanced. These models are already extremely capable, having undergone extensive pre-, mid-, and post-training, so the property that matters after deployment is no longer whether they retain old tasks, but whether they become more capable as the world they operate in changes. The community has approached this in fragments: continual learning as a memory problem (retrieval, in-context learning, context management), a steering problem (prompt optimization), a reasoning problem (reinforcement learning and distillation), and a compression problem (architectural updates). Each takes a different bet on what continual learning requires, but the field still lacks a shared frame in which those bets can be compared.
We take a different starting point. The change in the data that matters for continual learning has structure, and the operative question is not whether a method handles change, but which kind.
Continual learning is not one problem, and it is not solved.
Two · Framing
Space and time.
Continual learning is the problem of making a model more capable as the world it operates in changes, not just remembering old tasks. This definition lets us evaluate a wide range of methods on equal footing, whatever each one updates.
We measure capability by examining how a model learns under different kinds of data change. We separate those changes along two axes. Space is domain shift: a new task or distribution. Time holds the task fixed while the world drifts. We study two kinds: a selective change, where a single fact is updated while the rest must be preserved (facts edited between Wikipedia revisions), and a slow temporal drift, where the signal shifts gradually year over year (companies' annual 10-K financial filings). We order these from the more standard, literature-rooted tasks toward newer and more realistic ones, and return to each in turn.
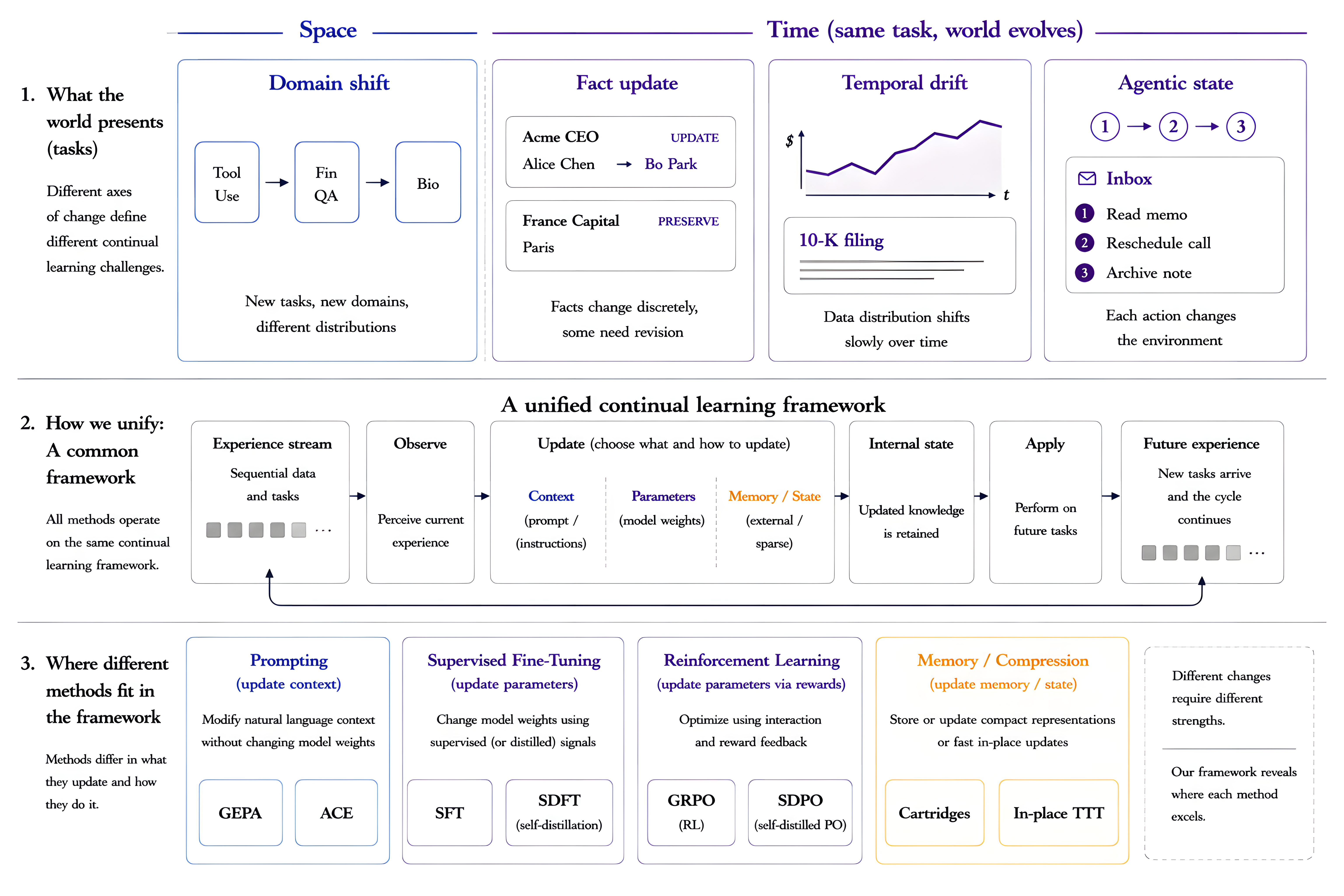
Most benchmarks measure a single static snapshot; each of these settings instead asks whether a model keeps improving as its world changes.
Three · Methods Overview
Eight methods tested.
Our framework recasts standard LLM benchmarks as sequential problems and evaluates every method under one mechanism-agnostic protocol, so prompt, weight, and architectural updates can be compared on equal ground. We run eight methods across four families on a single backbone (Qwen3-8B). They differ in what they carry across a stage boundary: a prompt, the weights, or a small per-stage component on a frozen backbone.
| Family | Method | Carries across a stage |
|---|---|---|
| Prompt | GEPA | evolved prompt |
| Prompt | ACE | markdown playbook |
| Supervised fine-tuning | SFT | full parameters |
| Supervised fine-tuning | SDFT | parameters + teacher (previous self) |
| Reinforcement learning | GRPO | full parameters |
| Reinforcement learning | SDPO | parameters + preference pool |
| Compression | Cartridges | backbone + per-stage adapter |
| Compression | In-Place TTT | per-input update (reset) |
Which method to use depends on the kind of change you face. Each cell is the best method in that family for that change; bold marks the best choice overall.
| Kind of change | Prompt | Supervised fine-tuning | Reinforcement learning | Compression |
|---|---|---|---|---|
| New domain or taskdisjoint tasks | GEPA* | SDFT | SDPO | Cartridges |
| Discrete fact changeWikipedia revisions | ACE | SDFT | GRPO | Cartridges |
| Noisy slow trend10-K filings | ACE | SDFT | SDPO | Cartridges |
| Agentic chainslong-horizon agent | Coming soon | |||
Bold marks the best choice overall; the other cells are the strongest option within that family, which may still be weak for a given change. *GEPA only if you keep a separate prompt per task.
No single method wins everywhere: distillation leads when knowledge must accumulate, on-policy RL when a fact must be overwritten, and the two prompt-only methods never win.
Four · Space: Domain Shift
Does experience compound across disjoint domains?
We train on three unrelated tasks in sequence: ToolUse, then FinQA, then SciKE-Bio. After each stage we evaluate on all three held-out sets, and the star marks the task just trained. A method that compounds skill raises the stars while keeping the other curves up.
- ToolUse — emit the correct tool calls, matching both the action names and their JSON arguments.
- FinQA — numerical question answering over financial documents.
- SciKE-Bio — answering biomedical knowledge questions.
ToolUse FinQA SciKE-Bio ★ = just-trained stage
Per-method accuracy across the three-stage chain. SDFT is the only method whose three end-of-chain scores are all above baseline. GEPA's mid-chain FinQA spike (≈ 53 %) is given back almost entirely at the Bio phase. Cartridges and In-place TTT barely move off the base-model row.Our sequential skill-learning protocol follows closely that of Shenfeld et al. (2026), who introduced it to study SDFT. We modify the task sets and evaluate all eight methods under it rather than SDFT alone.
Across disjoint domains, only distillation compounds: SDFT alone ends every stage at or above its zero-shot baseline.
Five · Time: Discrete Updates
When a fact changes, can the model rewrite the right one?
We construct a knowledge-update task from four monthly Wikipedia mirrors spanning November 2025 to February 2026. From each consecutive pair of snapshots we take a drift set of facts whose value changed, and a held-out stable set whose value did not, which gives three chronological slices. A method that learns the change should raise accuracy on the drift set while holding the stable set fixed. One that spreads the update across the whole model raises one and lowers the other, a failure we call catastrophic memorizing.
drift F1 (the facts to rewrite) stable F1 (the facts to leave alone) zero-shot drift baseline (per slice) zero-shot stable baseline
The x-axis is the three chronological slices, one per adjacent pair of the four monthly mirrors. GRPO is the only weight-update method whose drift F1 averages above baseline. SDFT's stable F1 falls from ≈ 0.30 to ≈ 0.17: it spreads the update across the model and erodes settled facts. Cartridges and In-place TTT keep stable F1 flat: locality, which hurt them on domain shift, is the property this regime rewards.The knowledge-update protocol likewise follows Shenfeld et al. (2026). We build our own monthly Wikipedia mirrors and, as above, compare all eight methods rather than SDFT alone.
Only GRPO rewrites a changed fact without erasing the rest; methods that anchor to the model's own past spread the change and damage settled facts.
Six · Time: Noisy Slow Trend
10-K filings, 2015 → 2020.
We construct a temporal-drift task from SEC 10-K filings spanning 2015 to 2020. A 10-K is the detailed annual report a public company files with the SEC on its financial performance. The task is fixed, predict whether a filer's stock moves up or down over the next thirty days, but the underlying market drifts year to year and the signal is weak. We measure whether a method can stay aligned with the slow trend without overfitting to a single year.
past-year avg future-year avg ★ zero-shot baseline
SDFT lifts future-year accuracy from ≈ 0.51 to ≈ 0.63 by 2020. Cartridges holds both halves around 0.55. GRPO's past-year curve drops from 0.65 to 0.42 across the chain: a noisy reward reinforces the wrong answer. GEPA peaks early and bleeds.For the prompting family, we look directly at the evolved prompt to see why it fails to transfer forward. GEPA discovers generic financial-analysis heuristics (right) rather than the moves of an ideal adaptive analyst (left): discarding irrelevant sections, normalizing sentiment relative to a sector or company baseline, or distinguishing newly informative elements from those already priced in by the market. It overfits to transient textual heuristics while failing to preserve signals that remain predictive out-of-sample.

Under a weak, drifting signal, methods anchored to their own past (SDFT, Cartridges) stay aligned; the anchoring that erased facts under selective updates pays off here, while on-policy RL amplifies the noise.
Seven · Takeaway
No single method handles every kind of change.
Continual learning is not a single capability. The kind of change in the data determines which update behavior succeeds.
Across our evaluations we observe a consistent set of tradeoffs. Prompt-based methods fit the current stage quickly but degrade sharply on future ones; distillation-based methods accumulate knowledge stably yet struggle to update outdated facts; context compression improves efficiency without substantially improving the ability to learn new tasks; and reinforcement learning adapts most effectively to factual change but remains sensitive to noisy reward signals. Because these tradeoffs cut in opposite directions across regimes, no single method in our comparison handles more than one regime well, and a single benchmark number cannot reveal whether a model is continually learning or merely reshuffling what it already knows.
| Method | Strength | Weakness |
|---|---|---|
| GEPA | Fits the current stage fastest. | Degrades on later stages; no per-task memory. |
| ACE | Fits fast; slightly more stable than GEPA. | Same forward degradation across stages. |
| SFT | Simple full fine-tune. | Overwrites prior skills; near chance under noisy drift. |
| SDFT | Accumulates skills stably. | Slow to overwrite a single outdated fact. |
| GRPO | Best at rewriting a changed fact. | Sensitive to noisy or weak reward. |
| SDPO | Stable accumulation, like SDFT. | Struggles to update discrete facts. |
| Cartridges | Most stable; cheap per-stage memory. | Learns little new-task skill. |
| In-Place TTT | Local, per-input adaptation. | Limited new-task acquisition. |
Our reframing is simple but important: improving a model's score on a benchmark is not the same as helping a model become more competent as time moves forward, which is the property that matters for practical deployment. Benchmarks reward the first; they largely miss the second.
Eight · What's Next
Agentic continual learning.
The benchmarks above each construct one kind of change in isolation. The closest setting to deployed use is an agent acting in an application across a chain of tasks, where the state left by one task becomes the starting point of the next. We build this on WebArena-Infinity: chains of web tasks of length L, in which step i+1 depends on state that step i leaves behind. In Gmail, the agent creates a label, renames it, then applies the renamed label to a specific email, and a verifier reads the app's state to check end-to-end success. Because the sequence arises from the agent's own actions rather than an ordering we imposed, we treat it as the most realistic instantiation of continual learning over time.
As a first look at whether experience compounds here, we add learning two ways: an ACE playbook on Qwen-32B, and supervised fine-tuning of Qwen-8B on the 32B agent's own traces. Both raise chain success over a no-learning baseline at every horizon length, with the largest gains on the three-step (L3) chains.
Qwen-32B (ACE) Qwen-8B (SFT) after, solid before, dashed
End-to-end chain success rate across chain lengths L1 to L5, with all four series on one axis. Color marks the model (blue Qwen-32B, red Qwen-8B); line style marks the stage, dashed for the zero-shot baseline and solid for the most-trained variant (the L10 ACE playbook on Qwen-32B, sft-L5 for Qwen-8B fine-tuned on the 32B agent's traces). Both models gain at every length, most on the three-step (L3) chains; the distilled 8B starts near zero past L1 and gains the most room.Cite This Page
@misc{harrington2026studying,
title = {Studying Learning in Continual Learning},
author = {Harrington, Anne and Saxena, Nayan and Murphy, Michael
and Borovykh, Anastasia and Yun, Zeyu and Kamath, Sridhar
and Kyi, Ara Eindra and Darrell, Trevor and Malik, Jitendra
and Bai, Yutong},
year = {2026},
howpublished = {\url{https://anneharrington.github.io/studying-cl}},
note = {Project page}
}